
关于SQLSERVER表分区的介绍(一)

时 间:2015-02-10 09:13:08
作 者:金宇转载 ID:43 城市:江阴
摘 要:很多时候当单张数据表的数据量比较大的时候比如千万级别条记录、上亿级别记录,如果不做优化,那么查询的效率大家清楚。有经验的人会通过各种手段做优化,其中表分区就是其中一种手段。
正 文:
有经验的人会通过各种手段做优化,其中表分区就是其中一种手段。
个人对表分区的口语化解释:把一张表分成几个区域
例如:一张业务表,有一个字段是月份或者年份,那么可以按照月份/年份来分区,当客户要查询某个月份/年份的数据的时候就到那个月份/年份的分区去查询,
不用整个表去查询,这样就提高了不小效率。还是就是可以把分区文件组放在不同的磁盘分区或者不同的硬盘去,减少磁盘I/O。
以上这些都是表分区的特点。
下面说一下概念吧~
SQLSERVER数据库服务器中包含很多数据库对象,其中就包括分区类对象。
分区类对象
分区类对象是对“分区方案”和“分区函数”两类对象的总称。SQLSERVER2005引入了数据表分区的概念。引入分区的目的是为了提高对数据表的维护,从而
提高数据库的性能。分区,即将一个原本的大数据表拆分成较小的多个数据表,由于需要查询的数据局限于空间的局部性,即查询的记录往往位于同一分区中,因此
通过分区,实际上可以将在大量数据集中进行查询的操作转换为在小部分数据中进行查询的操作,从而获得更快更高的查询效率。除此之外,将数据分区也有利于
数据库的维护操作(例如,重新生成索引或备份表也可以更快地运行)
实际操作过程中,也可以不拆分数据表,而是将数据表安排到不同磁盘驱动器上的方法来实现分区。例如,将数据表放在某个物理磁盘上并将相关的表放在不同
的磁盘驱动器上,同样可以提高查询性能,因为在运行涉及表间连接的查询时,多个磁头可以同时读取数据。可以使用SQLSERVER文件组来指定放置表的磁盘。
水平分区与垂直分区
如果将原有的大数据表拆分成多个小数据表,则通常被称为水平分区。水平分区的特点是每个分区中包含的列数是一样的,但是其中每个分区表中的记录数被
减少了。而与之对应的,还有一种被称为垂直分区的方案,即将一个数据表中的列划分为到多个结构较为简单的数据表中。
注意:推荐使用水分分区,这样应用程序的代码逻辑可以不变,实际上应用表分区(水平分区)之后跟应用之前对应用程序都是透明的!
在SQLSERVER2005中创建分区表的步骤如下:
(1)创建分区函数以指定如何分区,以及分区所涉及的数据表
(2)创建分区方案以指定分区函数的分区在文件组上的位置
(3)创建使用分区方案的表
一、分区函数
分区函数用于指定如何对数据表进行分区。分区函数可将数据表中指定部分映射到一组分区。因此在创建分区函数时需要指定分区数、分区依据列(即使用哪一列作为分区的参考列)
以及各分区依据列值的范围(即属于同一分区的各记录中,依据列值应满足的范围)。需要注意的是,在指定分区依据列时,只能指定一列。
打个比方:大数据表中有一列是时间列,如果按照月份来分区,那么分区数是12,分区依据列是时间列(时间列格式:XXXX-XX-XX XX:XX:XX),按照时间列中的月份来划分
范围,哪个时间属于哪个月份。
SQLSERVER2005中用于创建分区函数的T-SQL脚本命令是Create PARTITION FUNCTION。语法:
Create PARTITION FUNCTION partition_function_name(input_parameter_type)
AS RANGE[LEFT|RIGHT]
FOR VALUES([boundary_value[,...n] ])
[;]
其中参数partition_function_name为要创建的分区函数名,input_parameter_type为该函数的输入参数类型,该参数就是用于实现分区的依据列的数据类型。
而选项RANGE,通过LEFT (即小于)和RIGHT(即大于)来指定分区的约束条件,即是小于依据列的值、还是大于依据列的值。
参数boundary_value用于指定每个分区的边界值。
二、分区方案
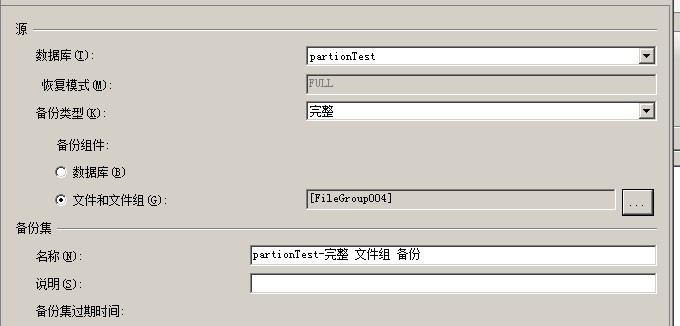
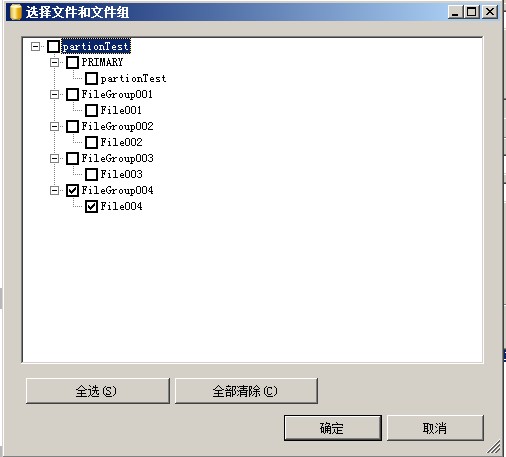
在计划分区方案时,必须决定要在哪个文件组上放置分区。将分区安排在独立的文件组上的主要优势是可以确保在分区上独立地执行备份操作。即分别对
每个独立的文件组进行备份(分区跟文件组进行映射,所以对文件\文件组备份相当于对分区进行备份)关于备份请看下面的补充。需要注意的是,在设计
分区方案之前,必须首先使用分区函数来指定分区的个数,以及每个分区的范围。即必须首先在Create PARTITION FUNCTION语句中创建分区函数,
然后才能创建分区方案。
使用T-SQL创建分区方案的语法如下所示:
Create PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ALL] TO ({file_group_name|[PRIMARY]}[,...n] )
[;]
其中参数partition_scheme_name为要创建的分区方案的名称。分区方案名称在数据库中必须是唯一的,并且符号标识符规则。参数partition_function_name
为需要使用的分区函数的名。由分区函数创建的分区将被映射到在分区方案中指定的文件组中。必须注意,partition_function_name应已存在于当前的数据库中。
如果在上述T-SQL语句中使用了选项ALL,就表明所有分区都将被映射到file_group_name中提供的文件组,或映射到主文件组(如果指定了[PRIMARY])
中(一般不使用ALL,如果使用了那么分多个文件组就没有意义了)。
补充:关于SQLSERVER中文件组备份
摘录自:http://www.e800.com.cn/articles/2007/0828/280690.shtml
当备份一个数据库时,一个选择是备份一个文件组而不是整个数据库。这对于大型数据库特别有用。一个大型数据库,取决于硬件,大概500GB,备份会花费几个小时。事实上,我曾看过一个系统花费四到五个小时去备份一个那么大的数据库。备份花费资源,并且可能并不值得每天晚上花五小时做完全备份工作。
这个问题有几种解决方案。我曾见过设定每周做一次完全备份,一系列事务日志和一整个星期执行的差异备份。这样可行,但是你每个星期将仍然需要一个长时间的单独窗口来做完全备份。
如果你将数据库分解为大小都差不多的七个文件组来替代, 那会怎么样呢?在那种情况下,它们都是72GB左右大小,并且你将每天晚上备份一个文件组。这会将原来很长的完全的备份缩短为七个较短的文件组的备份,并经过一个星期你将完成整个数据库的备份。我曾经用过一些包含海量数据的数据库,其相当大的一部分是只读的。
依据遵从性检查的要求,像Sarbanes-Oxley,一个大型的金融数据库大小可能为600GB或700GB,但经常大部分是回溯到七年或更久以前的历史数据。如果你有这样的数据库并且只有20%的数据有规律地改变,那你可能可以通过利用文件组来提高效率。把规律变化的表放到你的主要文件组里,把历史的或存档表放到一个存档文件组里。现在你可以每天备份主要文件组,或许一个星期或一个月备份一次存档文件组。
参考文献:http://it.china-b.com/sjk/sqlserver/20090826/176946_1.html
http://www.e800.com.cn/articles/2007/0828/280690.shtml
特别说一下,SQLSERVER备份的最小单位是文件组不是文件,所以备份跟恢复都是文件组不是文件
就写到这里吧~ 下篇介绍分区函数和分区方案的创建和使用方法
Access软件网官方交流QQ群 (群号:54525238) Access源码网店
相关文章:
 升级的诱惑(SQLSERVEREXPRESS2005) 【李制樯 2013/7/1】 判断MS SQLSERVER临时表是否存在 【smeyou 2013/9/30】 ACCESS转SQLSERVER后代码需要修改的语句 【杜威 2013/12/1】 SQL加速|升迁至SQLServer数据库后,如果存在左联接或者右联接的查询会很慢的解决方法 【金宇 2014/4/15】 SqlServer时间日期处理函数及字符串转换 【杜超-2号 2014/4/19】 SQLServer 2005提示:无法打开到主机localhost的连接 在端口 1433:连接失败 【网络 2014/4/20】 拆分MDB方式,ODBC链接SQLSERVER方式,adp方式--三种开发模式比较 【小华 2014/5/23】 SQLSERVER错误状态 【金宇【转载】 2014/11/4】
升级的诱惑(SQLSERVEREXPRESS2005) 【李制樯 2013/7/1】 判断MS SQLSERVER临时表是否存在 【smeyou 2013/9/30】 ACCESS转SQLSERVER后代码需要修改的语句 【杜威 2013/12/1】 SQL加速|升迁至SQLServer数据库后,如果存在左联接或者右联接的查询会很慢的解决方法 【金宇 2014/4/15】 SqlServer时间日期处理函数及字符串转换 【杜超-2号 2014/4/19】 SQLServer 2005提示:无法打开到主机localhost的连接 在端口 1433:连接失败 【网络 2014/4/20】 拆分MDB方式,ODBC链接SQLSERVER方式,adp方式--三种开发模式比较 【小华 2014/5/23】 SQLSERVER错误状态 【金宇【转载】 2014/11/4】Access网店:

Access快速开发平台--操作员只能查看自己的数据,管理员可以查看所有数据
价格:¥500 元.gif)
Access快速开发平台--打印预览选中的多项记录示例
价格:¥100 元
【Access报表】打印查询结果到报表,多条件查询符合条件的记录并用报表打印
价格:¥50 元
常见问答:
技术分类:
源码示例
- 【源码QQ群号19834647...(12.17)
- 统计当月之前(不含当月)的记录...(03.11)
- 【Access Inputbo...(03.03)
- 按回车键后光标移动到下一条记录...(02.12)
- 【Access Dsum示例】...(02.07)
- Access对子窗体的数据进行...(02.05)
- 【Access高效办公】上月累...(01.09)
- 【Access高效办公】上月累...(01.06)
- 【Access Inputbo...(12.23)
- 【Access Dsum示例】...(12.16)

学习心得

最新文章
- 32位的Access软件转化为64...(04.12)
- 【Access高效办公】如何让vb...(04.11)
- 仓库管理实战课程(10)-入库功能...(04.08)
- Access快速开发平台--Fun...(04.07)
- 仓库管理实战课程(9)-开发往来单...(04.02)
- 仓库管理实战课程(8)-商品信息功...(04.01)
- 仓库管理实战课程(7)-链接表(03.31)
- 仓库管理实战课程(6)-创建查询(03.29)
- 仓库管理实战课程(5)-字段属性(03.27)
- 设备装配出入库管理系统;基于Acc...(03.24)
专栏作家
