
���� SQL Server �淶����
ʱ����:2019-06-23 13:08:26
������:���� ID��21115 ���У��Ϻ�
ժ��Ҫ:���� SQL Server �淶����
������:
�������ֶ�����ѡ��
1.�ַ����ͽ������varchar/nvarchar��������
2.�����ҽ������money��������
3.��ѧ�����������numeric��������
4.��������ʶ�������bigint�������� (������һ����int���;�װ���£����Ժ������鷳��)
5.ʱ�����ͽ������Ϊdatetime��������
6.��ֹʹ��text��ntext��image�ϵ���������
7.��ֹʹ��xml�������͡�varchar(max)��nvarchar(max)
Լ��������
ÿ�ű�����������
- ÿ�ű�����������������ǿ��ʵ��������
- ����ֻ����һ��������������Ϊ�ռ��ظ����ݣ�
- ����ʹ�õ��ֶ�����
������ʹ�����
- ��������˱��ṹ���������Ǩ�Ƶĸ�����
- ����Բ��룬���µ�������Ӱ�죬��Ҫ��������Լ��
- �����������ɳ������
NULL����
�¼ӵı��������ֶν�ֹNULL
���±�Ϊʲô������NULL��
����NULLֵ��������Ӧ�ó���ĸ����ԡ������������ض��������룬�Է�ֹ���ָ��������bug
��ֵ�������еȺţ�"="���IJ�ѯ����������isnull���жϡ�
Null=Null��Null!=Null��not(Null=Null)��not(Null!=Null)��Ϊunknown����Ϊtrue��
������˵��һ�£�
����������������ͼ��ʾ��
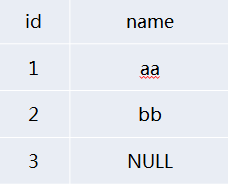
�������Ҳ��ҳ���name����aa���������ݣ�Ȼ����Ͳ����������Select * FROM NULLTEST Where NAME<>'aa'
���������Ԥ�ڲ�һ������ʵ����ֻ�����name=bb��û�в��ҳ�name=NULL�����ݼ�¼
��������β��ҳ���name����aa���������ݣ�ֻ����ISNULL������
Select * FROM NULLTEST Where ISNULL(NAME,1)<>'aa'
���Ǵ�ҿ��ܲ�֪��ISNULL����������ص�����ƿ�� ,���Ժܶ�ʱ���������Ӧ�ò��������û������룬ȷ���û�������Ч�������ٽ��в�ѯ��
�ɱ��¼��ֶΣ���Ҫ����ΪNULL������ȫ�����ݸ��� �����ڳ��������������������Ҫ�ǿ���֮ǰ���ĸ������⣩
���������
- Ӧ�ö� Where �Ӿ��о���ʹ�õ��д�������
- Ӧ�öԾ����������ӱ����д�������
- Ӧ�ö� orDER BY �Ӿ��о���ʹ�õ��д�������
- ��Ӧ�ö�С�͵ı�����ʹ�ü���ҳ�ı�������������������Ϊ��ȫ��ɨ��������ܱ�ʹ������ִ�еIJ�ѯ��
- ����������������6��
- ��Ҫ��ѡ���Ե͵��ֶν���������
- �������ΨһԼ��
- �����������ֶβ�����5��������include�У�
��Ҫ��ѡ���Ե͵��ֶδ�����������
- SQL SERVER�������ֶε�ѡ������Ҫ�����ѡ����̫��SQL SERVER�����ʹ��
- ���ʺϴ����������ֶΣ��Ա�0/1��TRUE/FALSE
- �ʺϴ����������ֶΣ�ORDERID��UID��
�������Ψһ����
Ψһ������SQL Server�ṩ��ȷ��ijһ�о���û���ظ�ֵ����Ϣ������ѯ������ͨ��Ψһ�������ҵ�һ����¼��������˳������������������
��������������6��
��������������6�����������ֻ��Я��DBA��������֮���ƶ��ġ�������
- �����ӿ��˲�ѯ�ٶȣ�����ȴ��Ӱ��д������
- һ����������Ӧ�ý���������ص�����SQL�ۺϴ����������ϲ�
- ���������ԭ���ǣ�������Խ�õ��ֶ�Խ��ǰ
- ��������������ӱ���ʱ�䣬Ҳ��Ӱ�����ݿ�ѡ�����ִ�мƻ�
SQL��ѯ
- ��ֹ�����ݿ�����������
- ��ֹʹ��Select *
- ��ֹ����������ʹ�ú��������
- ��ֹʹ���α�
- ��ֹʹ�ô�����
- ��ֹ�ڲ�ѯ��ָ������
- ����/����/�����ֶ����ͱ������ֶ�����һ��
- ��������ѯ
- ����JOIN����
- ����SQL��䳤�ȼ�IN�Ӿ����
- ����������������
- �ر�Ӱ����м�����Ϣ����
- ���DZ�ҪSelect��䶼�������NOLOCK
- ʹ��UNION ALL�滻UNION
- ��ѯ��������ʹ�÷�ҳ��TOP
- �ݹ��ѯ�㼶����
- NOT EXISTS���NOT IN
- ��ʱ���������
- ʹ�ñ��ر���ѡ����ӹִ�мƻ�
- ��������ʹ��OR�����
- ���������쳣��������
- �����ʹ�ö���ʽ������ʽ
��ֹ�����ݿ�����������
- XML����
- �ַ��������ԱȽ�
- �ַ���������Charindex��
- ���������ڳ�������
��ֹʹ��Select *
- �����ڴ����ĺ��������
- ����ѯ�Ż����л����������ȡ����Ҫ����
- ���ṹ�仯ʱ���������ѯ����
��ֹ����������ʹ�ú��������
��where�Ӿ���,��������Ǻ�����һ����,�Ż���������ʹ��������ʹ��ȫ��ɨ��
�������ֶ�Col1�Ͻ���һ�������������г�������ʹ�õ�������
ABS[Col1]=1
[Col1]+1>9
�پ���˵��һ��

�����������IJ�ѯ�������õ�O_OrderProcess���ϵ�PrintTime��������������Ӧ��ʹ��������ʾ�IJ�ѯSQL
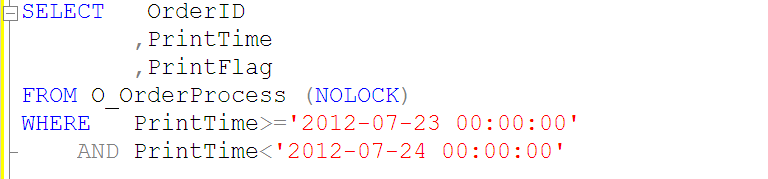
��ֹ����������ʹ�ú��������
�������ֶ�Col1�Ͻ���һ�������������г���������ʹ�õ�������
[Col1]=3.14
[Col1]>100
[Col1] BETWEEN 0 AND 99
[Col1] LIKE 'abc%'
[Col1] IN(2,3,5,7)
LIKE��ѯ����������
1.[Col1] like ��abc%�� �Cindex seek ������õ���������ѯ
2.[Col1] like ��%abc%�� �Cindex scan ������Ͳ�δ�õ�������ѯ
3.[Col1] like ��%abc�� �Cindex scan ���Ҳ��δ�õ�������ѯ
������϶����������У����Ӧ�����ף���ò�Ҫ��LIKE����ǰ����ģ��ƥ�䣬������ò���������ѯ��
��ֹʹ���α�
��ϵ���ݿ��ʺϼ��ϲ�����Ҳ���Ƕ���Where�Ӿ��ѡ����ȷ���Ľ���������ϲ������α����ṩ��һ���Ǽ��ϲ�����;����һ������£��α�ʵ�ֵĹ��������൱�ڿͻ��˵�һ��ѭ��ʵ�ֵĹ��ܡ�
�α��ǰѽ�������ڷ������ڴ棬��ͨ��ѭ��һ��һ��������¼�������ݿ���Դ���ر����ڴ������Դ���������Ƿdz���ġ�
���ټ����α����ıȽϸ��ӣ�ͦ�����õģ��������ðɣ�
��ֹʹ�ô�����
��������Ӧ�ò�����Ӧ�ò��涼��֪����ʲôʱ��������������ҲҲ��֪�����о�Ī��������
��ֹ�ڲ�ѯ��ָ������
With(index=XXX)�� �ڲ�ѯ������ָ������һ�㶼��With(index=XXX) ��
- �������ݵı仯��ѯ���ָ�����������ܿ��ܲ������
- ������Ӧ��Ӧ�����ģ���ָ����������ɾ�����ᵼ�²�ѯ����������������
- �½�����������Ӧ������ʹ�ã�����ͨ���������������Ч
����/����/�����ֶ����ͱ������ֶ�����һ�£�������֮ǰ��̫��ע�ģ�
��������ת���������ĵ�CPU������Ĵ��scan��Ϊ����
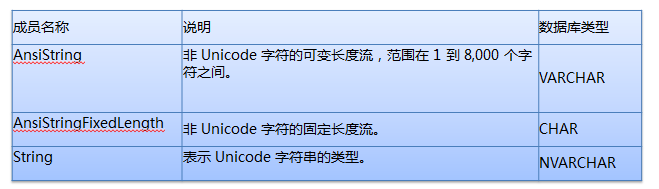
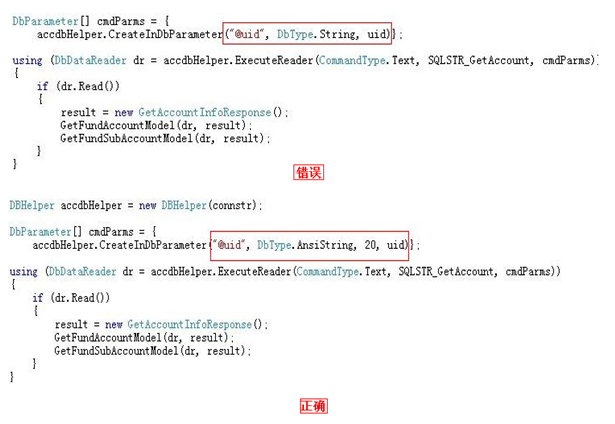
��������������ͼ�������Ҳ��ý���˵������Ҷ�Ӧ���Ѿ�����˰ɡ�
������ݿ��ֶ�����ΪVARCHAR����Ӧ�������������ָ��ΪAnsiString����ȷָ���䳤��
������ݿ��ֶ�����ΪCHAR����Ӧ�������������ָ��ΪAnsiStringFixedLength����ȷָ���䳤��
������ݿ��ֶ�����ΪNVARCHAR����Ӧ�������������ָ��ΪString����ȷָ���䳤��
��������ѯ
���·�ʽ���ԶԲ�ѯSQL���в�������
sp_executesql
Prepared Queries
Stored procedures
��ͼ��˵��һ�£�������


����JOIN����
- ����SQL���ı�JOIN�������ܳ���5��
- �����JOIN�����ᵼ�²�ѯ�������ߴ�ִ�мƻ�
- ����JOIN�ڱ���ִ�мƻ�ʱ���ĺܴ�
����IN�Ӿ�����������
�� IN �Ӿ��а��������dz����ֵ������ǧ�ƣ����ܻ�������Դ�����ش��� 8623 �� 8632��Ҫ��IN�Ӿ�����������������100������
����������������
- ֻ��������Ҫ����ʱ��ʼ��������Դ������ʱ��
- ���������쳣����Ԥ��������
- ��ֹʹ�����ݿ��ϵķֲ�ʽ����
��ͼ��˵��һ��
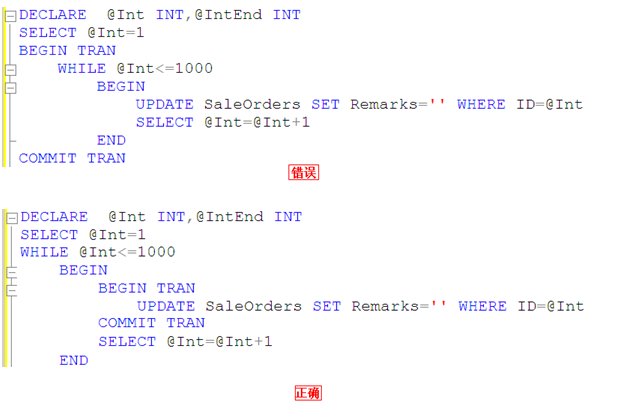
Ҳ����˵���Dz�Ӧ����1000�����ݶ��������֮����commit tran,���������ڸ�����һǧ�����ݵ�ʱ���Dz��Ƕ�ռ��Դ��������������������
�ر�Ӱ����м�����Ϣ����
��SQL�������ʾ����Set Nocount On��ȡ��Ӱ����м�����Ϣ���أ�������������
���DZ�ҪSelect��䶼�������NOLOCK
���DZ�Ҫ�����������е�select��䶼�������NOLOCK
ָ���������������������������ֹ���������ĵ�ǰ�����ȡ�����ݣ����������� �õ������������谭��ǰ�����ȡ�������ݡ�����������ܲ����϶�IJ�����������������Ƕ�ȡ�Ժ�ᱻ��������ع��������ġ�����ܻ�ʹ����������������û���ʾ��δ�ύ�������ݣ����ߵ����û����ο�����¼���������������¼��
ʹ��UNION ALL�滻UNION
ʹ��UNION ALL�滻UNION
UNION���SQL�����ȥ����������CPU���ڴ������
��ѯ��������ʹ�÷�ҳ��TOP
�������Ƽ�¼������������IO�������������ƿ��
�ݹ��ѯ�������
ʹ�� MAXRECURSION ����ֹ�������ĵݹ� CTE ��������ѭ��
��ʱ���������
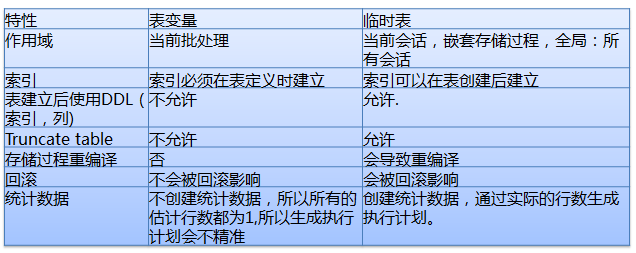
ʹ�ñ��ر���ѡ����ӹִ�мƻ�
�ڴ洢���̻��ѯ�У�������һ�����ݷֲ��ܲ�ƽ���ı��������������ô洢���̻��ѯʹ���˴��������ڽϲ��ִ�мƻ��ϣ����High CPU������IO Read�����⣬ʹ�ñ��ر�����ֹ�ߴ�ִ�мƻ���
���ñ��ر����ķ�ʽ��SQL�ڱ����ʱ���Dz�֪��������ر�����ֵ����ʱ��SQL����ݱ��������ݵ�һ��ֲ���"�²�"һ������ֵ�������û��ڵ��ô洢���̻�����ʱ�����ı���ֵ�Ƕ��٣����ɵļƻ�����һ���ġ������ļƻ�һ���Ƚ���ӹһЩ����һ�������ŵļƻ�����һ��Ҳ���������ļƻ�
�����ѯ�б��ر���ʹ���˲���ʽ���������ѯ������ʹ����һ���� 30% ����ʽ��Ԥ��
Estimated Rows =(Total Rows * 30)/100
�����ѯ�б��ر���ʹ���˵�ʽ����������ѯ������ʹ�ã���ȷ�� * ����¼������Ԥ��
Estimated Rows = Density * Total Rows
��������ʹ��OR�����
����OR�������ͨ����ʹ��ȫ��ɨ�裬���Ƿֽ�ɶ����ѯ��UNION/UNION ALL��ʵ�֣�����Ҫȷ�ϲ�ѯ���ߵ����������ؽ��ٵĽ����
���������쳣��������
Ӧ�ó����������������ʱ��Rollback��
������������ ��set xact_abort on��
�����ʹ�ö���ʽ������ʽ
����ʽ������ʽ������.�ֶ���
��JOIN��ϵ��TSQL���ֶα���ָ���ֶ��������ĸ����ģ�����δ�����ṹ������п��ܷ���Ambiguous column name�ij�����ݴ���
�ܹ����
- �����
- schema����
- ������������
�����
- ���֮���Ϳ��Ƕ�д���룬���¶�дͬһ���⣬�����ڿ�������
- ���ն������Ѷ���Ϊʵʱ���Ϳ��ӳٶ��ֱ��Ӧ��д��Ͷ���
- ��д����Ӧ�ÿ����ڶ�������������Զ��л���д��
Schema����
��ֹ���JOIN
������������
�������ݵ�ʹ��Ƶ���ȣ��Դ�����ڷֿ�鵵
����/�鵵����������
��־���͵ı�Ӧ������ֱ�
���ڴ�ı���Ҫ���з��������������������������ڶ��������ͨ�������л��ܹ�����ʵ���¾ɷ����滻���ӿ����������ٶȣ��������IO��Դ����
Ƶ��д��ı�����Ҫ������ֱ�
��������Latch Lock
������sql Server�Լ��ڲ�����Ϳ��ƣ��û�û�а취����Ԥ��������֤�ڴ��������ݽṹ��һ���ԣ���������ҳ����
Access������QQ����Ⱥ (Ⱥ��:54525238) ������������AccessԴ������
�������:
 SQL Server ���ݿ�������õ�SQL��T-SQL��� ������ 2019/1/23�� ACCESS����SQL SERVERд���ͻ ���Ϲ� 2019/3/21�� SQL Server��ȡ���Ľṹ���� ����� 2019/5/24�� ���ٿ���ƽ̨��ҵ��̳̣�SQL Server���ݿ��Զ����ݼ�������־���� ���쳾���� 2019/6/1�� SQLServer�������Զ���ŵķ��� ������ 2019/6/12��
SQL Server ���ݿ�������õ�SQL��T-SQL��� ������ 2019/1/23�� ACCESS����SQL SERVERд���ͻ ���Ϲ� 2019/3/21�� SQL Server��ȡ���Ľṹ���� ����� 2019/5/24�� ���ٿ���ƽ̨��ҵ��̳̣�SQL Server���ݿ��Զ����ݼ�������־���� ���쳾���� 2019/6/1�� SQLServer�������Զ���ŵķ��� ������ 2019/6/12��Access����:

.gif)

�����ʴ�:
��������:
Դ��ʾ��
- ��Դ��QQȺ��19834647...(12.17)
- Access���Ӵ������ݽ�����...(10.30)
- ������Ͽ�����Դ���ݿ�����...(10.25)
- Access��ƽ̨�Ķ�ֵѡ����...(10.24)
- ��Access��������β�ѯ��...(10.22)
- ��AccessԴ��ʾ����VBA...(10.12)
- Access�۳�ʾ����Acce...(10.09)
- ��ֵ8.88��������8ȥ����ת...(10.08)
- ��Access�Զ��庯����һ��...(09.30)
- ��Accessѡ�ʾ����Ac...(09.09)

ѧϰ�ĵ�
- ����Ŀ������˾��������ϵͳ��Acces...
- ������Ŀ��ͬ����ϵͳ������Access...
- ��Access������������Ϣ����ϵͳ��
- �����żƻ���Ϣ����ƽ̨������Acces...
- ��TMSƽ̨���� �����㲿����Ӧ���г�...
- ���ز����Ž���ϵͳ��ʹ��ǿ����Acce...
- ���ֿ����ϵͳ��access���ݿ����...
- ����ҵ����ͬ����ϵͳ����Access...
- ��Access�ʹ���ƽ̨������Ⱦ���䷽...
- ��ҽ����������ϵͳ��Ϊ��ʹ�ҵĹ�������...

��������
- Access�ж϶�����ϸ���䷽��...(11.30)
- ����ú�̨���ݿ��ھ���������ʱ����...(11.29)
- ��Access�³���ĩ�������÷���...(11.29)
- ��Access IIF����Ƕ��ʾ��...(11.26)
- Access���ٿ���ƽ̨--ʹ����...(11.25)
- Access���ٿ���ƽ̨--���ϴ�...(11.22)
- Access���ٿ���ƽ̨��ҵ��--...(11.18)
- �����ö�����ϲ�ѯ�������ѯû���...(11.16)
- �����������������ֶ�ֵ���в���Ͽ�...(11.16)
- Access���ٿ���ƽ̨--��̨D...(11.14)